DeepSymphony - Conditional Polyphonic Music Generation
Aim
The aim of this project is to produce a monophonic (single-instrument) chord accompaniment music track for a given single-channel melody.
Sample Input
Generated Output
Data-set
We have used the Christian Hymn Dataset which contains 3385 hymns represented in MIDI files. For each hymn, we had two MIDI files : the leading melody file and the final accompaniment track.
The dataset was found from here : https://github.com/wayne391/Symbolic-Musical-Datasets
Data-preparation
The downloaded MIDI files for the same hymn were often of different lengths. This means that the melody and accompaniment tracks for the same hymn were sometimes padded with silence. These padding were removed, the tracks were converted to numpy array.
The initial songs were all in different keys, which made learning very difficult. Thus, after referring MuseGAN, all the songs were shifted to a common Key (C-major Key) using the following script:
import glob
import os
import music21
majors = dict([("A-", 4),("A", 3),("B-", 2),("B", 1),("C", 0),("D-", -1),("D", -2),("E-", -3),("E", -4),("F", -5),("G-", 6),("G", 5)])
minors = dict([("A-", 1),("A", 0),("B-", -1),("B", -2),("C", -3),("D-", -4),("D", -5),("E-", 6),("E", 5),("F", 4),("G-", 3),("G", 2)])
for file in glob.glob("*.mid"):
try:
score = music21.converter.parse(file)
key = score.analyze('key')
if key.mode == "major":
halfSteps = majors[key.tonic.name]
elif key.mode == "minor":
halfSteps = minors[key.tonic.name]
newscore = score.transpose(halfSteps)
key = newscore.analyze('key')
newFileName = "../transposed/" + file
newscore.write('midi',newFileName)
except:
pass
Usefull Libraries for Music Pre-processing
Pypianoroll is a python package for handling multi-track piano-rolls built by the creators of MuseGAN. Features :
- handle piano-rolls of multiple tracks with metadata
- utilities for manipulating piano-rolls
- save to and load from .npz files using efficient sparse matrix format
- parse from and write to MIDI files
Simple LSTM
A simple 1-layer LSTM sequence-to-sequence (1-to-1 architecture) network was used. The network trained very slowly, taking 6 hours for 10 epochs.
- Loss function : Binary Cross-entropy
- Optimizer : Adam. Learning Rate = 0.001
- Batch-Size : 64
Given Melody :
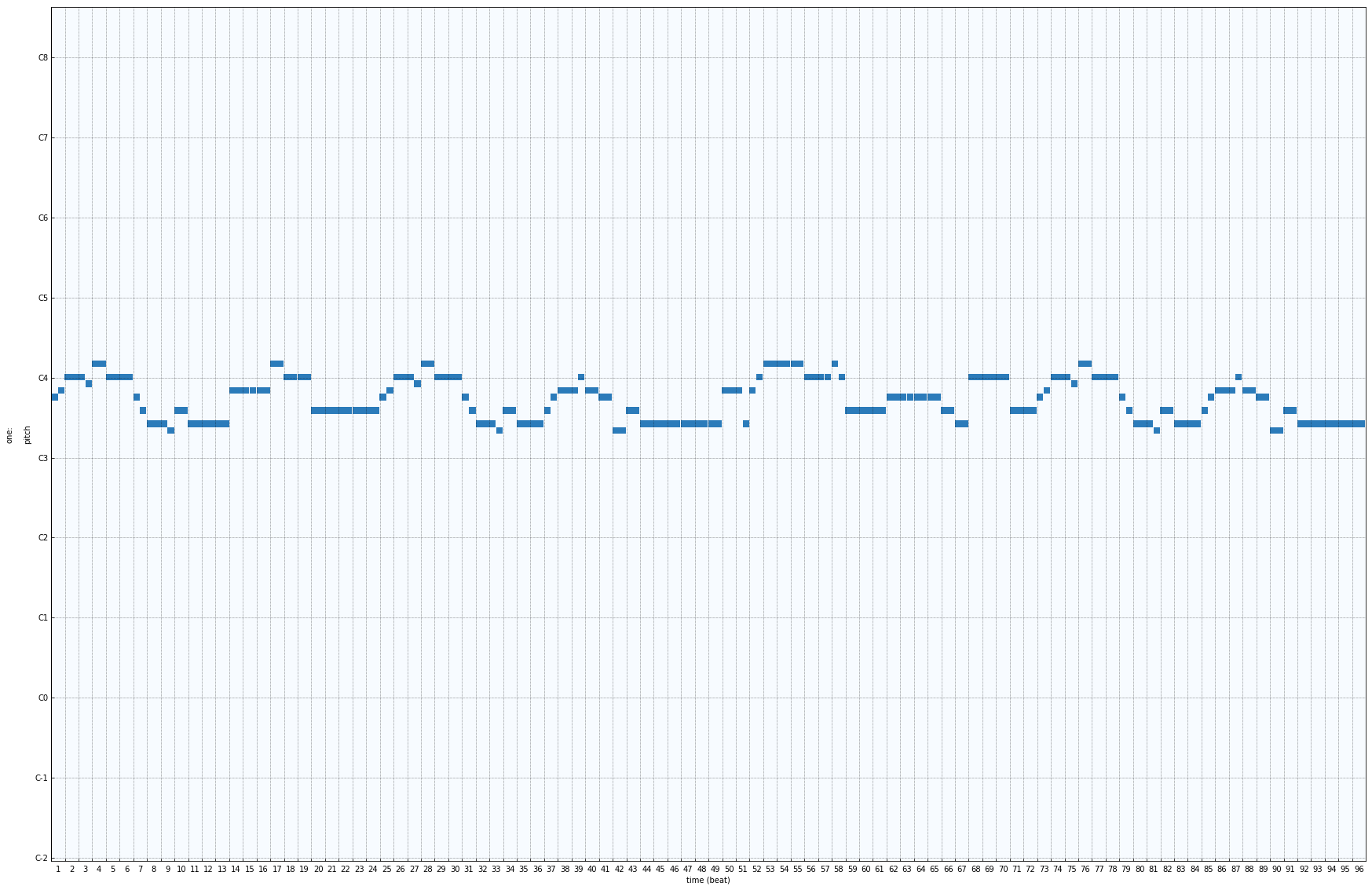
Expected Accompaniment :
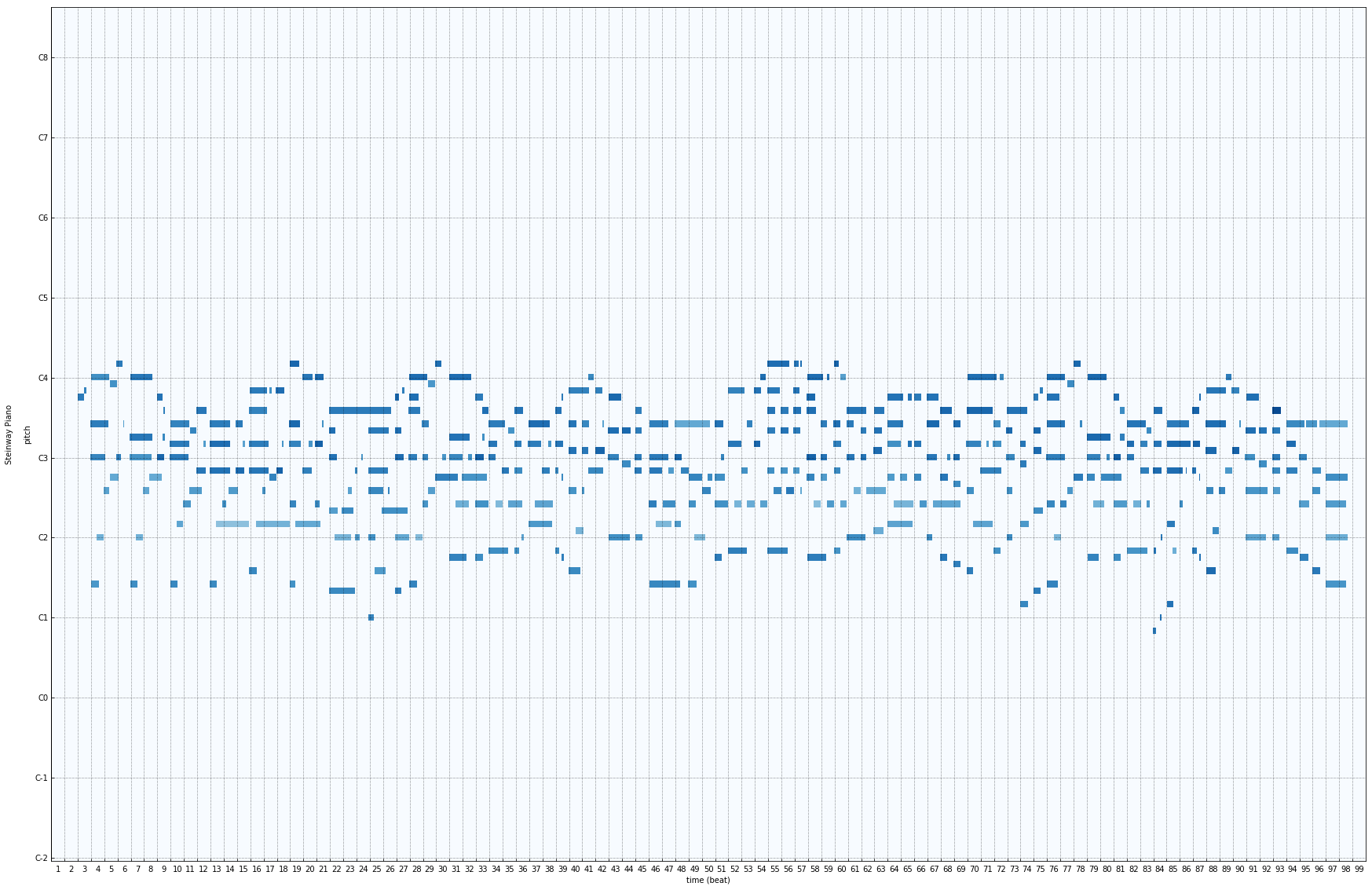
Results :
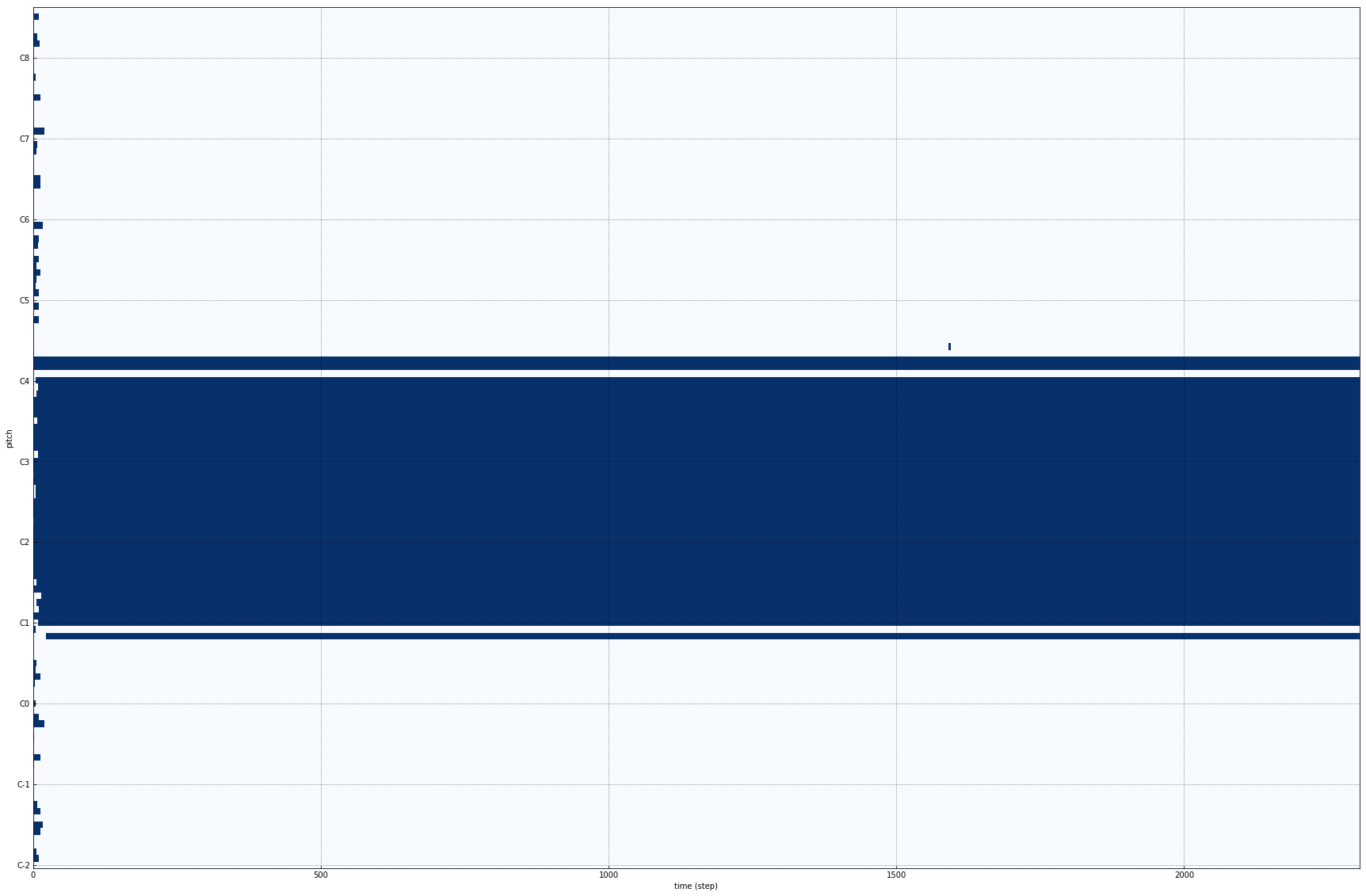
The above model clearly fails to achieve anything. It learns where the notes are being played, but due to large batch size, cannot produce any good results. We tried reducing the batch-size to 1, but the results were more or less the same.
LSTM with Truncated Back-Propogation
Major Changes in this Model
-
Optimizers :
After some variations with the optimizers, we figured out RMS-Prop is the easily the best choice. Even the official Keras Documentation recommends using RMS-Prop for Recurrent Neural Networks.
The image (Source) below shows the performance shows the general performance of various Optimizers -
Truncating Back-Propogation :
Back-Propogation Through Time can be slow to train LSTM on problems with very long input sequences. In addition to speed, the accumulation of gradients over so many timesteps can result in a shrinking of values to zero, or a growth of values that eventually overflow, or explode.
So, we divided the sequence into smaller sub-sequences for implementing Truncated Back-Propogation Through Time. -
Many-to-One-to-Many Sequence-to-Sequence
Source

Variations Tried
- Model-1 : 2-layer Bi-LSTM with sequence_length = 40
- Model-2 : 2-layer Bi-LSTM with sequence_length = 20
- Model-3 : 4-layer Bi-Stacked LSTM with sequence_length = 10

Results
Given Melody :
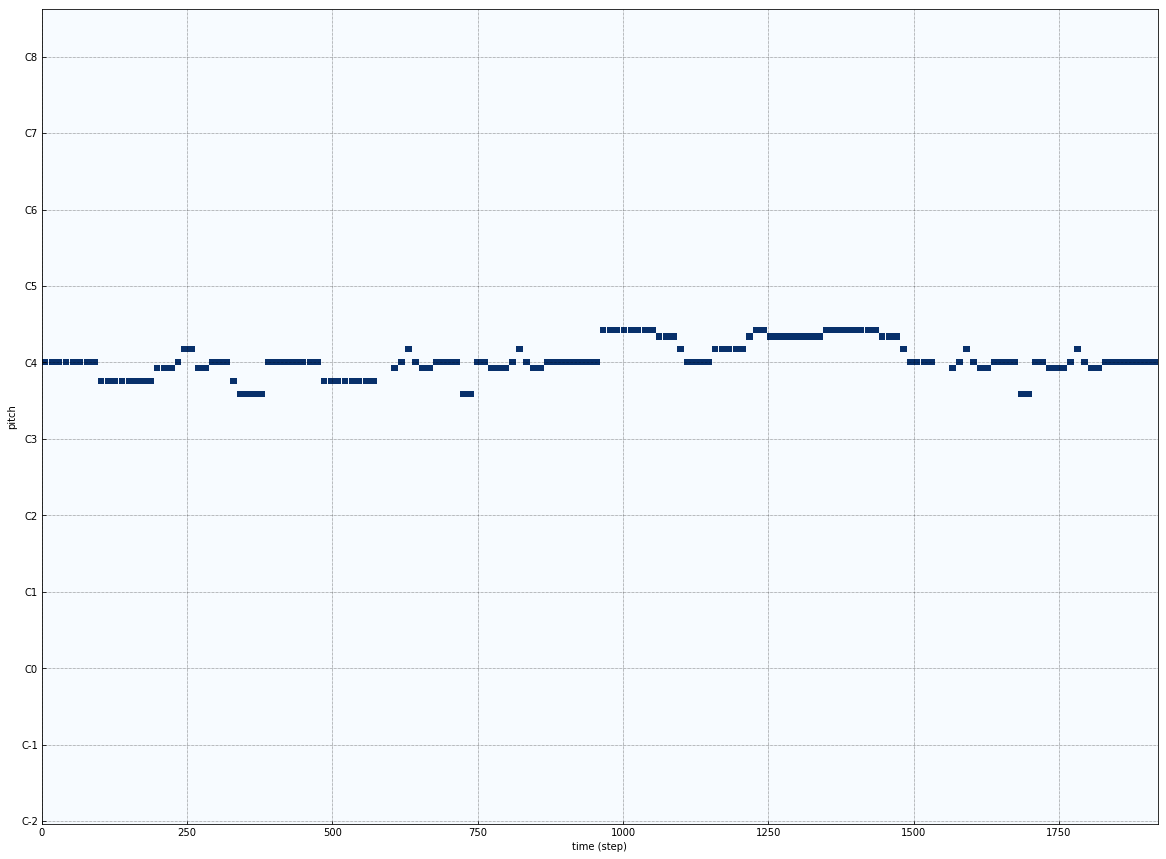
Expected Output :
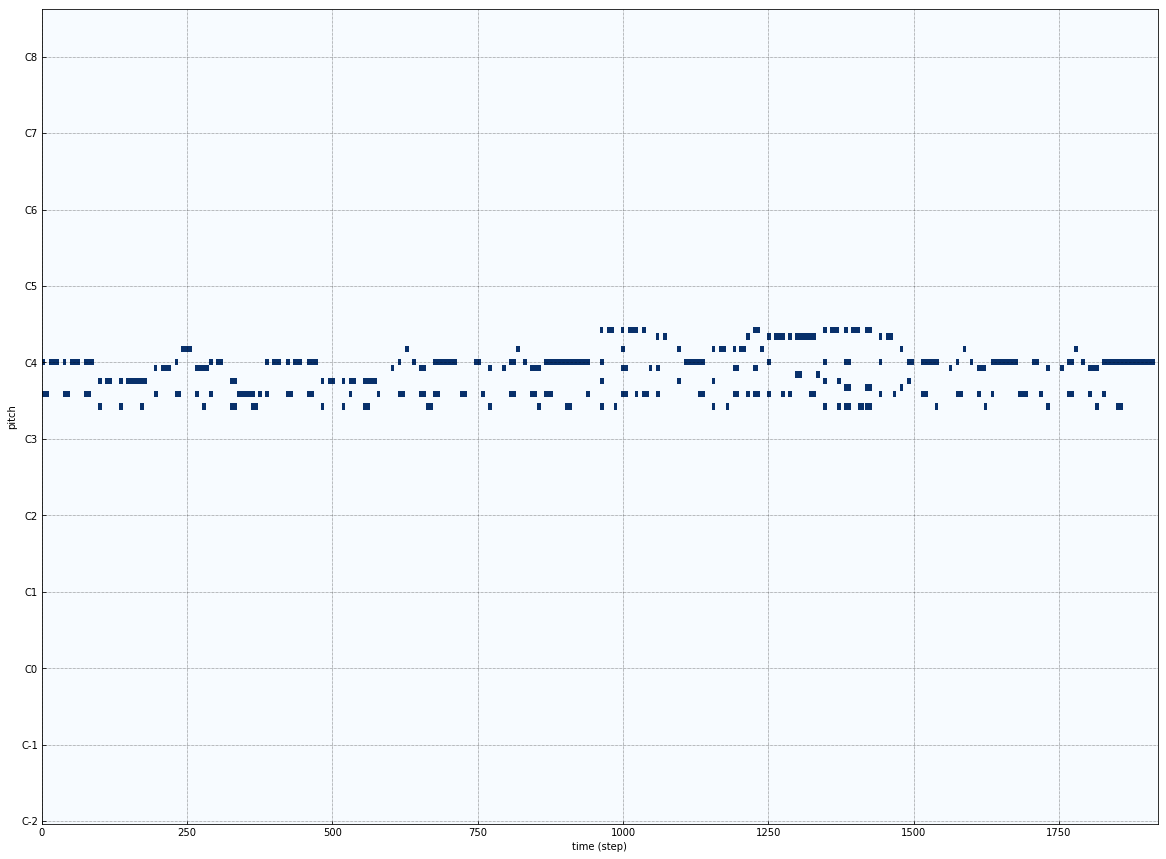
Model-1 : 40-timestamp sequence
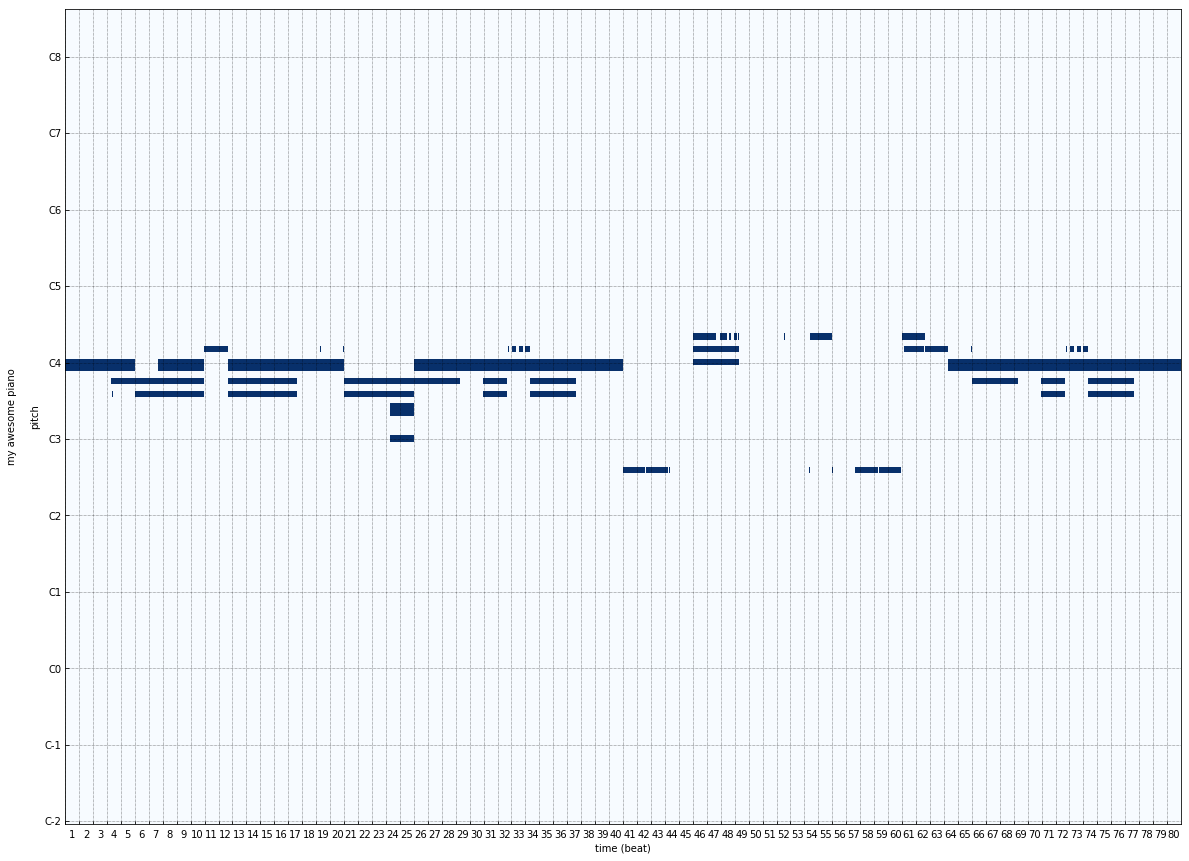
Model-2 : 20-timestamp sequence
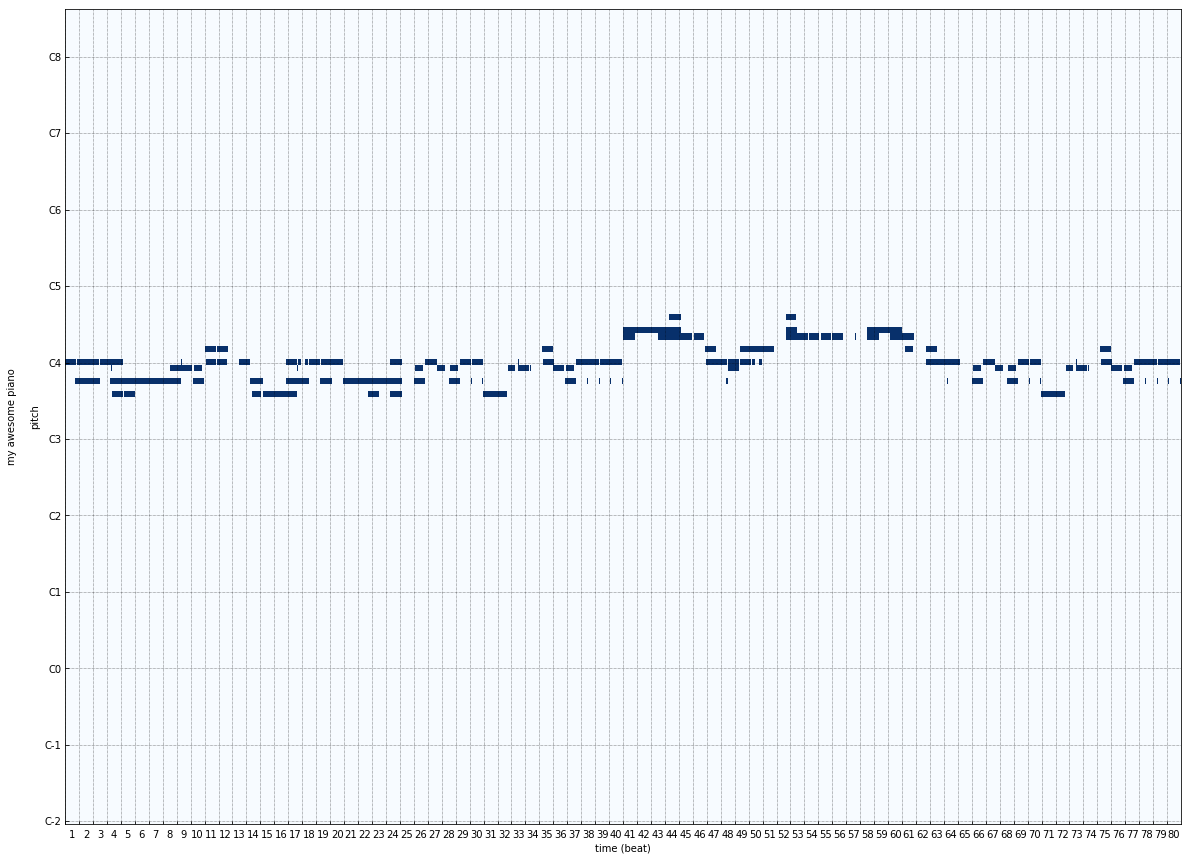
Model-3 : 10-timestamp sequence
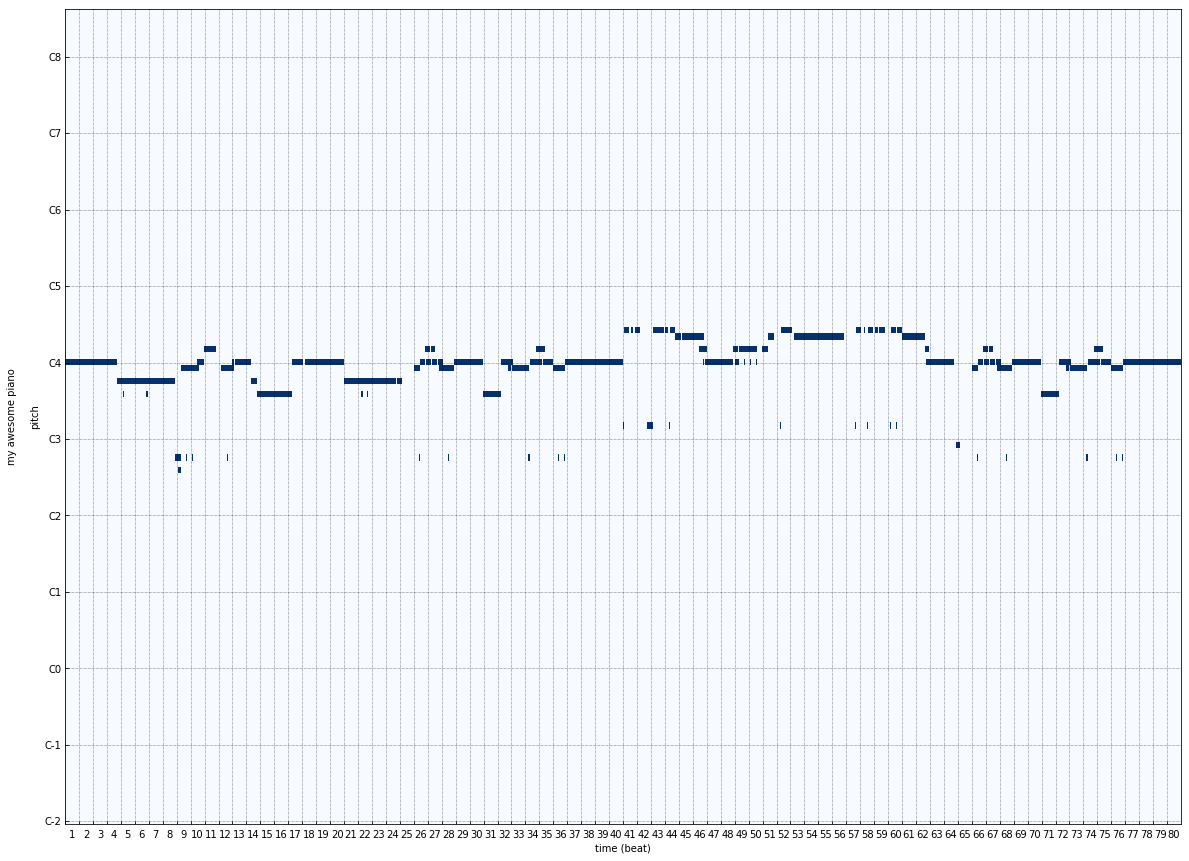
Conclusion
We see that for sub-sequence length 20 and 10, the LSTM is able to accurately learn the melody part and some part of accompaniment. This may be due to the varying complex nature of accompaniment and the less number of epochs.
Sample Input
Expected Output
Output-1
Output-2
Learning Outcome
- Truncated Back-propogation
- Different LSTM architectures for Seq-2-Seq
- Working with music data(MIDI)
- Effects of different optimizers on LSTMs